
Technical
The Road to RBAC: Evaluating and Implementing Authorization Systems
Mike Cugini

Early on in our development journey, we decided to use SaaS options where it made development significantly faster or where the problem being solved was not a core differentiator to our product.
This guideline led us to take on Auth0 early on. Similarly, we recently worked on bringing Role Based Authorization Controls (RBAC) to Prodvana. We had the opportunity to evaluate whether or not any Authz SaaS solutions made sense for us to offload this.
At its core, Prodvana is a deployment workflow product. This means it’s the source of truth for deployment configuration and status but also has the power to change the production environment.
Providing RBAC is important so our customers can safely delegate access to their team members scoped to what they need. For example, read-only visibility can be granted to the organization, Product Engineers can only deploy code changes in their area, and Platform Engineers can connect cloud infrastructure.
Our Options
While the immediate goal was to implement a role-based system, we wanted to ensure the implementation choices now allow us to expand to a fine-grained access control system (FGAC). So before jumping into the implementation, we explored the SaaS and open-source Authz systems.
As outlined above, the role-based approach limits both the type of resources a user can act on and the actions they can take on them. The main enhancement over RBAC is the ability to scope the role-based capabilities to specific resource instances. For example, instead of giving a Service Owner permission to deploy Services for all Applications, we could scope it to just a single Application or a specific set of Services.
There’s a delicate balance to be struck here — on the one hand, we want to avoid drawing ourselves into a corner, but on the other hand, introducing any external dependency like this brings with it more complexity both in terms of deployment as well as integration (e.g., mapping our data model into theirs, handling the inevitable interface mismatch).
We already use SaaS solutions in other parts of the product, but outside of Auth0, none would lead to availability issues if they were down. Authentication is likely a once-a-day operation, so the risk of visible user disruptions from a service blip is relatively low. In contrast, Authorization decisions are made at least once per user interaction. Because of this, we also wanted to optimize for options that run locally or provide a caching layer within our infrastructure.
Here’s a quick summary of what we considered; more details follow:
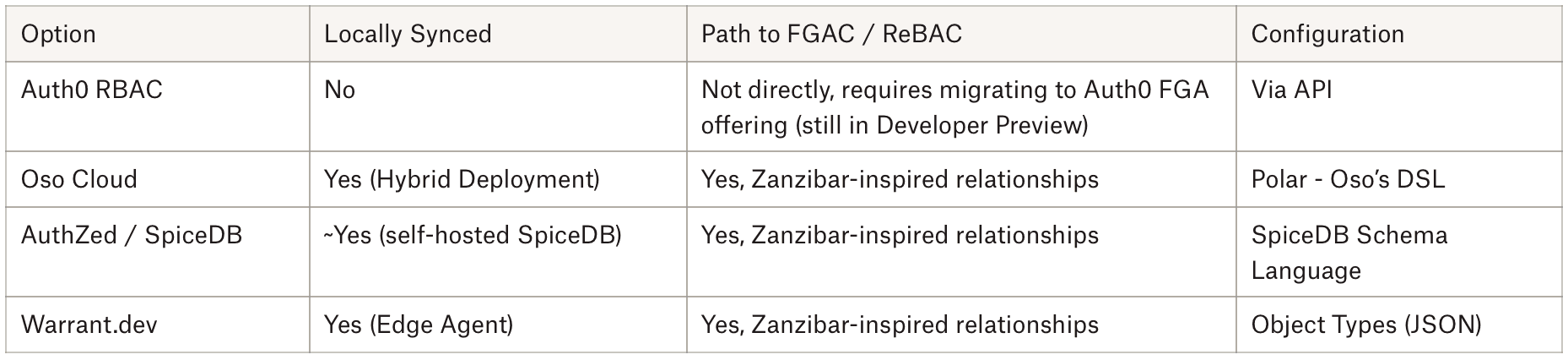
We use Auth0 as our authentication provider, so it made sense to first look at Auth0’s authorization offerings. Auth0 has an integrated RBAC system that allows for basic modeling of roles mapped to a set of what they call permissions. An earlier, limited prototype of RBAC had been implemented using this.
This seemed like a good start — so does it support expanding to fine-grained access?
Unfortunately, not directly. Auth0 has a Fine-Grained Authorization offering, but it is separate from the RBAC model and has been stuck in “Dev Preview” for at least six months. Since FGA lacked a GA release, we would likely sign up for a migration as the offering changed. Overall, it did not meet the requirements without a path forward from the RBAC model and with no client-side syncing solution.
The remaining options, Oso, AuthZed, and Warrant, are all modeled after Google Zanzibar. While they each have different schemas for building out the access model, each one can model both RBAC and FGAC relationships. As outlined above, each has a solution for managing the local or cached state.
This brings us to the crux of our decision — maintaining an external representation of our still-evolving data model adds significant overhead. None of these options make it easy to define and keep in sync with our internal model. We decided to sidestep the complexity entirely and keep Authz in-house.
How We Modelled RBAC
While we decided on rolling our own implementation for now, we wanted to leave the door open for the Authz implementation to be swapped in the future. So, in our business logic, the Authz provider is implemented as an interface to abstract away the underlying mechanics.
On top of that, we needed to leave hooks in this interface to be able to support FGAC as well.
Prodvana has three core resources to delegate access to Applications, Services, and Runtimes, and we have defined four roles for managing access to these resources.
Viewer - Read-Only
Service Owner - Viewer capabilities + the ability to modify Applications and Services and deploy Services.
Cloud Admin - Service Owner capabilities + the ability to modify Runtimes
Org Admin - Full administrative privileges
The interface we came up with looks like this:
(Yes, one area for cleanup here will be splitting each resource into its type).
Each method represents an Action (create, configure, delete) that can be taken against a particular resource (Application,Service). User identification information is passed through the context, and the remaining parameters provide the resource identifiers needed for fine-grained control.
In the current implementation, the resource identifiers are ignored — but the data is being plumbed through appropriately, so the calling code won’t need to change when we allocate the time for implementing FGAC.
In our concrete RBACAuthorizer, we define each role as a set of Capabilities, where a Capability is a combination of a Resource and an Action. When a user is assigned a role, they are assigned a set of Capabilities. Implementing it this way makes it easier to support custom roles in the future.
For example, a slimmed-down definition of the Viewer role looks like this:
Then storing user to role mappings is just mapping the Role’s identifier to the user:
Then, in the RBACAuthorizor methods, we can look up a user’s Capability set and check if they have the Capabilities needed to perform that specific Action. One caveat is when the first user signs up for Prodvana. These users are marked as the creator of the organization and on first log in, are automatically assigned Org Admin privileges (this user is not otherwise special, and this role can be removed as long as there’s at least one other Org Admin user).
Future Work
Custom Roles
As mentioned above, the data model is flexible enough to support defining custom roles since a role is already represented as a set of Capabilities. Adding custom role support requires mapping our database between custom role identifiers and their Capabilities.
Capability Pre-Checks
In the current model, we make Authz decisions when a user takes an action. For example, if a user clicks a Service's“Delete” button, the Authz decision is made in the RPC call the click triggers. So, if the user did not have permission, they would see an authorization error. From a user experience perspective, it would be better if the “Delete” button was greyed out and unclickable.
This requires pre-checks where the front end asks, “Can this user take this action?”. Implementing this is a little trickier. The frontend client knows what RPC it will call but doesn’t know what Capability (or Capabilities) calling RPC requires.
Teams / Groups
Currently, roles can only be applied directly to users with teams or groups on the horizon. This will allow roles to be defined for members of the teams or groups in one location. This is also useful for customers who want to map groups from their Identity Provider (Okta, ActiveDirectory, etc.), so newly provisioned users are automatically granted the correct role in Prodvana.
FGAC
Last, as you may have realized, this model's most significant future extension will be fine-grained Authz (did we mention that enough ). The biggest thing missing from the model explained above is the relationship between a user (or a team/group) and a particular resource instance.
Takeaways
Keep your authorization model in your application data store for as long as possible.
SaaS options that require extensively duplicating internal data models in an external system are more difficult to integrate.
It’s easier to think about Authorization in terms of what Capabilities a user should have from the start — this keeps the model flexible without complicating querying.
Keeping domain-specific code isolated behind interfaces makes it easier to swap out implementations later.
If you found this blog interesting, please check out our other content!






